项目背景
生物样本库通常用来保存血液、基因、代谢产物等珍贵的生物样本。生物样本保存在冻存盒内的冻存管中,并整盒存放于-80°甚至-196°的深低温环境中。为提高存取效率,当用户需要提取样本时,由自动化设备将存有目标样本的冻存盒取出,并使用机械臂夹取目标样本到空冻存盒中完成样本出库,并在-30°环境下使用挑管夹爪夹取目标样本到空冻存盒中完成样本出库。深低温保存条件下,冻存盒体表面会逐渐结霜。在零度以下的工作环境中反复移动、定位和出入库的过程,会导致结霜表面逐渐增厚,盒体发生轻微滑动,盒底孔位结霜干扰识别。长期使用中会导致挑管时盒体定位精度下降,夹爪取放位置误差增大,造成挑管成功率下降,严重时可能损坏样本,造成重大的损失。另外,当出现样本管倾倒等异常情况时,难以通过孔位识别进行定位抓取,也会导致挑管失败。
因此,项目需要一套视觉辅助的机械臂挑管系统,能够实现精准的抓取与稳定的路径规划,同时在检测到样本管异常情况时控制机械臂调整样本管位姿并放置到目标位置。在正常工作环境下,机械臂3轴移动即可实现样本管的平稳运送。但在样本管异常放置情况下,倾斜样本管的位姿调整与移送要求机械臂实现6自由度动作,并能够基于环境理解进行智能抓取。

个人分工
在本项目中,我将综合应用3D视觉技术和深度学习算法,解决不同形态和大小的医用物品在复杂环境中的抓取问题。首先,通过高效的图像分割技术,我们能够准确地将目标物品从其环境中区分出来,为抓取任务提供了精确的空间定位。进而,利用高级的姿态估计算法,系统能够计算出机械臂执行任务时的最优姿态,确保安全、精确的抓取。最后,通过智能规划,系统得以确定最佳的抓取顺序,旨在优化作业效率和成功率。整个系统的设计均考虑到边缘计算环境的资源限制,确保所有计算过程能在英伟达Orin边缘计算模块上以5hz以上的速度运行,展示了在现代自动化医疗场景中3D视觉技术的巨大潜力和实用价值。
-
抓取物品的图像分割
在复杂的医疗物品抓取任务中,准确的图像分割是实现高效抓取的关键。面对各种形态和尺寸的医用物品(如疫苗管、试管等),我们首先要利用3D视觉技术精确地将这些物品从背景中分割出来。这一步骤需要处理可能出现的物体间遮挡、光照变化以及物体本身的反光材质等问题。图像分割算法需要有足够的鲁棒性,以适应医疗环境中多变的条件。通过对3D点云数据的深度学习处理,能够实现对各种医用物品和它们的空间位置的精确识别,从而为后续的抓取姿态估计和序列规划提供可靠的前处理数据。
-
机械臂最佳抓取姿态估计
根据图像分割结果,系统需要进一步估计机械臂的最佳抓取姿态。使用3D视觉技术构建目标物体的高精度立体模型,结合机器学习算法对抓取点的稳定性和可行性进行评估。抓取姿态涉及到物体的方向、机械臂的接近角度和路径规划等多个要素。我们当中采用优化算法来确保最终推导出的抓取姿态既能增强抓取的成功率,又能最大限度减少机械臂的运动时间和能耗。姿态估计模块必须实时工作,以适应动态变化的抓取环境和任务需求。
-
医疗物品抓取顺序的计算
确定合理的抓取顺序对于提高整体抓取效率和成功率具有至关重要的意义。考虑到各种医疗物品之间的空间布局和相互关联,系统需要计算出一个最优的抓取顺序。这一过程包含复杂的逻辑和规划算法,例如,可能需要优先抓取会对后续操作造成遮挡的物品,或者根据任务紧急性来调整抓取顺序。适配边缘计算的算法需要考虑到计算资源和响应时间的限制,确保在有限的硬件资源下也能够快速给出最优解决方案。
文献调研+开题答辩
(见如下文件)
3D视觉识别及其在机器人抓取中的应用-开题答辩PPT.pdf
环境搭建
硬件层面
-
NVIDIA Jetson Orin NX 16GB
配备了高性能的英伟达GPU和多核CPU,算力高达每秒275万亿次浮点运算(TOPS),适合处理复杂的深度学习任务;提供了多种I/O接口和丰富的软件生态;同时具有紧凑的尺寸和优秀的能效比。

-
ZED 2i双目深度相机
具备高精度的深度感知能力,拥有广泛的视场(FOV),提供高分辨率的RGB图像;支持Jetson L4T操作系统,提供了全面的软件开发工具包(SDK),并为特定AI应用做了优化。

-
12V 5A电源适配器
-
罗技MK275无线键鼠
-
Redmi显示器A24-100hz

软件层面
-
安装Nvidia Jetpack
Nvidia Jetpack是专为Jetson平台设计的构建人工智能应用的全面的解决方案,它包括带有引导程序的Linux驱动程序包、Linux内核、Ubuntu桌面环境,以及一整套用于加速GPU计算、多媒体、图形和计算机视觉的库。参考英伟达官方教程,用命令行方式安装jetpack
1
2
3
4
5sudo apt update
sudo apt upgrade
sudo apt dist-upgrade
sudo reboot
sudo apt install nvidia-jetpack执行最后一步命令出现报错:

解决办法:为系统源增加英伟达镜像源
-
首先查看Tegra处理器的Linux操作系统版本:
cat /etc/nv_tegra_release
可以看到是L4T 35.3的版本
-
然后
sudo gedit /etc/apt/sources.list.d/nvidia-l4t-apt-source.list -
在文件中添加以下两行
1
2deb https://repo.download.nvidia.com/jetson/common r35.3 main
deb https://repo.download.nvidia.com/jetson/t234 r35.3 main保存后关闭
-
重启系统后重新执行前文的命令行即可
-
-
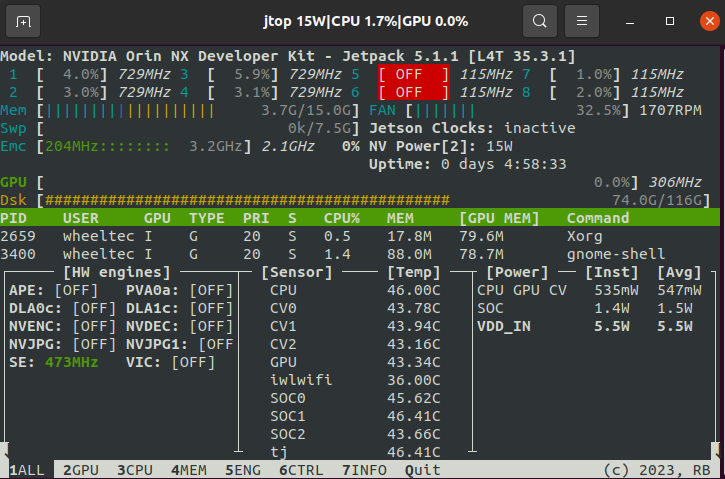
安装jtop监控工具
jtop是Jetson系列著名的系统监控工具,安装过程如下:
1
2
3
4sudo apt install python3-pip
sudo -H pip3 install -U pip
sudo -H pip install jetson-stats
jtop执行完最后一条命令,可显示包含CPU、GPU、内存和磁盘等实时情况的图形界面
-
为CUDA设置环境变量
在终端中修改bashrc文件,方法如下:
1
2
3
4
5
6
7gedit ~/.bashrc
在文末添加如下代码
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda
更新环境变量配置
source ~/.bashrc检验CUDA环境配置成功:
nvcc -V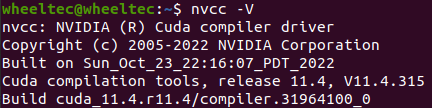
-
配置CuDNN环境
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16复制文件到cuda目录下
cd /usr/include && sudo cp cudnn* /usr/local/cuda/include
cd /usr/lib/aarch64-linux-gnu && sudo cp libcudnn* /usr/local/cuda/lib64
修改文件权限
sudo chmod 774 /usr/local/cuda/include/cudnn.h
sudo chmod 774 /usr/local/cuda/lib64/libcudnn*
重新软链接(8.6.0为cudnn版本号)
cd /usr/local/cuda/lib64
sudo ln -sf libcudnn.so.8.6.0 libcudnn.so.8
sudo ln -sf libcudnn_ops_train.so.8.6.0 libcudnn_ops_train.so.8
sudo ln -sf libcudnn_ops_infer.so.8.6.0 libcudnn_ops_infer.so.8
sudo ln -sf libcudnn_adv_train.so.8.6.0 libcudnn_adv_train.so.8
sudo ln -sf libcudnn_adv_infer.so.8.6.0 libcudnn_adv_infer.so.8
sudo ln -sf libcudnn_cnn_train.so.8.6.0 libcudnn_cnn_train.so.8
sudo ln -sf libcudnn_cnn_infer.so.8.6.0 libcudnn_cnn_infer.so.8
sudo ldconfig检验CuDNN环境配置成功:
dpkg -l libcudnn8
-
安装Anaconda虚拟环境
使用清华镜像源下载Anaconda,根据系统版本选择最新的Anaconda3-2023.09-0-Linux-aarch64.sh,按照提示安装并运行即可。
1
2
3
4conda --version # conda 23.11.0
conda create -n ZED_Python python=3.8
source activate ZED_Python
conda install xxx -
安装ZED SDK
在stereolabs官网选择适合系统版本的文件下载,然后执行命令
1
2sudo apt install zstd
./ZED_SDK_Tegra_L4T35.3_v4.0.8.zstd.run在安装ZED Python API的过程中遇到报错:
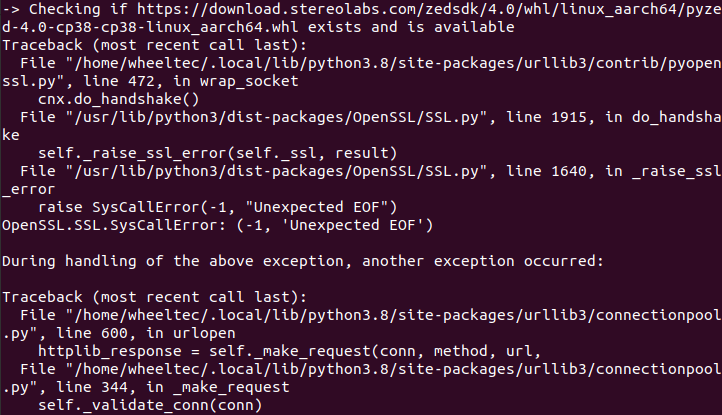
可能是连接服务器超时导致的,手动下载whl二进制文件并安装,注释掉相应代码重新执行命令并成功。
接下来测试Jetson和ZED硬件连接是否畅通:
首先应确保将相机插入USB3.0端口(内部有蓝色标记),以保证足够的带宽和传输速度;其次需从官网下载校准文件至安装目录的settings文件夹,该文件包含有关左右相机的精确位置及其光学特性的信息,是深度估计过程的关键(获取相机序列号的命令:
ZED_Explorer --all)最后运行
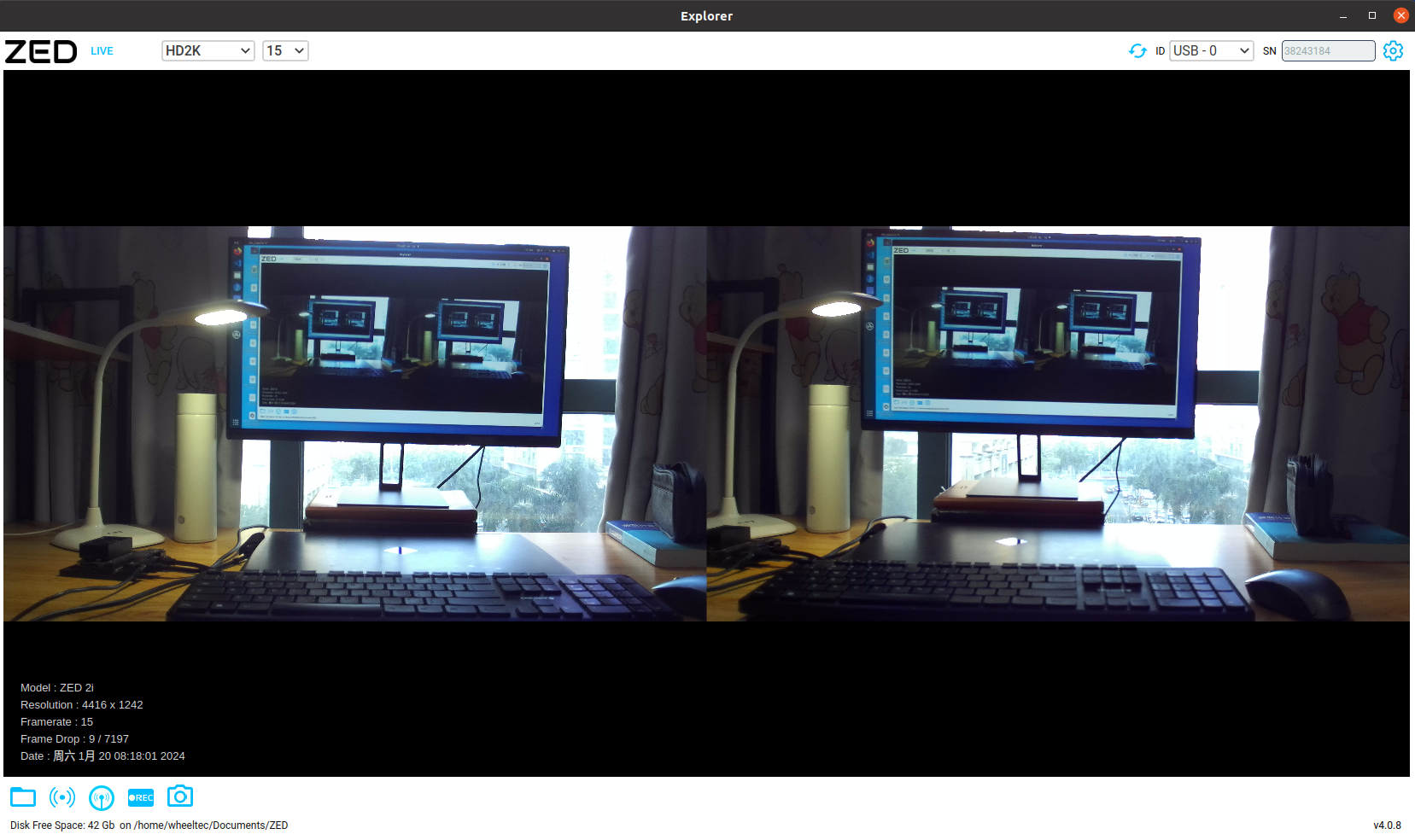
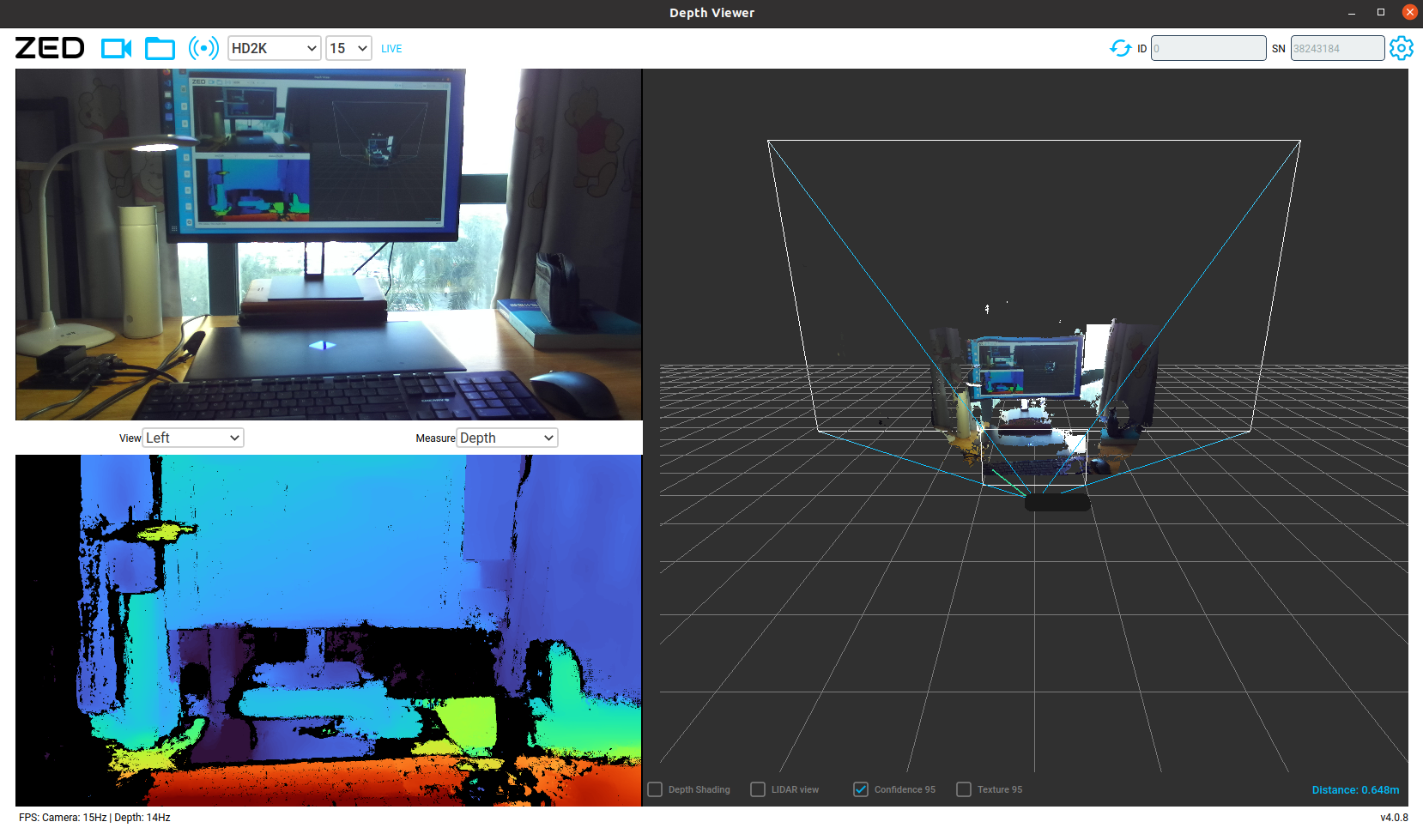
/usr/local/zed/tools目录下的应用程序ZED_Explorer和ZED_Depth_Viewer,运行效果如下:
| ZED_Explorer | ZED_Depth_Viewer |
|---|---|
 |
 |
第一部分:图像分割
本部分的阶段性目标:通过3D视觉技术将试管及冻存盒从背景中分割出来,实现对目标试管的精准定位,为机械臂抓取姿态的估计做准备性工作。本部分要求图像分割算法具有足够的鲁棒性,以适应物体间遮挡、光照变化以及反光材质等复杂的应用环境。
Hough圆变换
本项目将主摄像头安装在试管底部负责定位孔位,机械臂上的备用摄像头用于试管抓取异常时的排障。考虑到试管底部呈圆形,且粘有白色贴纸与黑色冻存盒能产生强烈反差,故联想到使用Canny边缘检测器和Hough圆变换的方法定位试管。
Canny边缘检测可分为以下四个步骤:
-
去除噪声:使用高斯滤波器对图像进行平滑处理以减少噪声。将二维高斯函数离散化后,即得高斯滤波器的计算公式${G(x, y) = \frac{1}{2\pi\sigma^2} e{-\frac{x2 + y2}{2\sigma2}}}$,其中${G(x,y)}$是一个像素点,${\sigma}$是高斯滤波器的标准差.
-
梯度计算:计算图像中每个像素点的梯度强度和方向,常通过Sobel算子来完成。
-
非极大值抑制:遍历梯度矩阵上的所有点,并保留边缘方向上具有极大值的像素为边缘候选点,否则将该点的梯度值设置为0,以消除对边缘检测的影响。
-
双阈值检测和边缘连接:通过设定高低两个阈值来识别强边缘和弱边缘。强边缘是确定的边缘点,而弱边缘则可能是边缘也可能不是。若弱边缘与强边缘相连,则认为它是真正的边缘;否则,将其抑制。
在边缘检测的基础上,霍夫变换原理可用于在图像中识别圆形物体,具体步骤如下:
-
霍夫空间映射:在霍夫空间中,每个边缘点可以表示为一系列可能的圆,这些圆有不同的中心和半径。在霍夫空间中,这转化为在三维空间(圆心的x坐标、y坐标和半径)上的一个点集。
-
累加器:在霍夫空间中,为每个可能的圆心和半径设置一个累加器。每次一个边缘点在霍夫空间中对应一个圆时,该圆的累加器值就增加。
-
寻找显著圆:在累加器中,值最大的点对应的圆心和半径被选为实际存在的圆。通过设定一个阈值可确定哪些累加器值足够高时可以表示一个圆。
霍夫圆检测特别适用于图像中圆形物体的位置不明确或有部分遮挡的情况。通过霍夫变换,即使只有圆的一部分边缘可见,也能有效地检测出完整的圆。
结合opencv的HoughCircles函数和ZED提供的python API,编写代码如下:
1 | # HoughCircles.py |
实际运行效果如下:
AprilTag
AprilTag是一个免费开源的视觉定位系统,用于物体的识别、定位和姿态估计,在增强现实、机器人、相机校准等领域广泛使用。Apriltag的设计旨在通过识别特定的二维码标记,快速检测并计算出相机相对于标记的位置和方向。
安装过程
在Conda虚拟环境中通过CMake安装第三方库过程如下:(附Github Repo)
1 | git clone https://github.com/AprilRobotics/apriltag |
编译libopencv时出现报错:
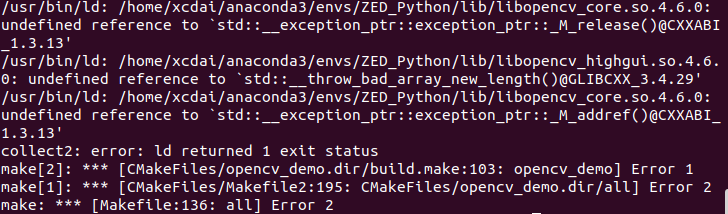
分析:在系统python解释器和conda环境中同时安装了libopencv,同时创建了两个关于libopencv的cmake文件(且两个版本不兼容),在编译的时候有find_package(OpenCV ...),这一步本应寻找/usr/lib/x86_64-linux-gnu/cmake/opencv4/OpenCVConfig.cmake这个文件,但由于安装了anaconda这一步变为寻找${CONDA_PREFIX}/lib/cmake/opencv4/OpenCVConfig.cmake这个文件,导致后续编译时链接的库文件出错。解决方法是限定要寻找的Qt5config.cmake文件路径,即在CMakeLists.txt里添加SET(CMAKE_PREFIX_PATH "/usr/lib/x86_64-linux-gnu/cmake"),重新编译即可解决问题。
编程
由AprilRobotics提供的apriltag缺乏姿态估计和可视化的部分,而Tinker-Twins提供了相应的库函数和demo,输出中包含标签的唯一标识符、置信度、单应矩阵、位姿矩阵等重要信息。以下代码是直接调用其编写的Detector类实现的。
1 | # apriltagVideo.py |
实际运行效果如下:
边缘检测
使用Sobel算子计算深度图的梯度,计算梯度幅值并标准化,采用阈值提取冻存盒边缘。
目前主要难题:双目还原点云很不稳定,精度很差
Halcon
基于形状的模板匹配
单相机标定
标定前需要生成一个标定板的描述文件.descr,标定板的参数由gen_caltab指定,具体用法如下:
1 | gen_caltab(7, 7, 0.2, 0.5, 'caltab.descr ', 'caltab.ps') |
参数:前两个依次表示x、y方向黑色标志圆点的数量,第三个表示两个相邻的黑色圆点之间的圆心距离(单位:m),第四个表示标记点直径与标记点圆心之间距离的比值,最后两个依次表示标定板的描述文件和图形文件的保存路径。
从不同角度拍摄12张图片(如下):

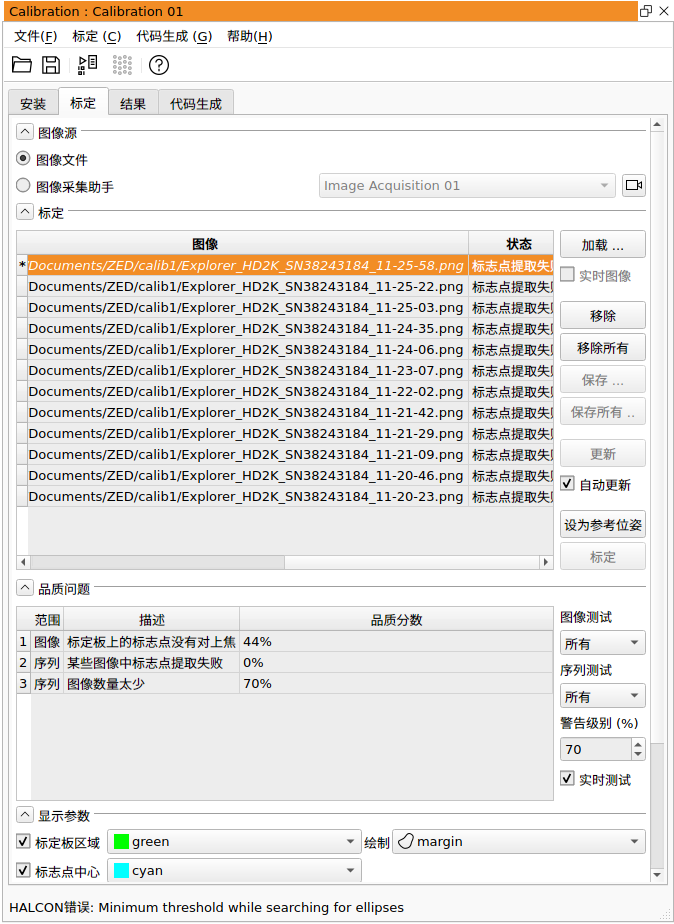
标志点提取失败: